2 Development Guide
2.1 Overview
Hiplot is dedicated to building an open and user-friendly platform for sharing plotting tools. Through the intuitive drag-and-drop component creation, users can transform plotting code into highly usable graphical tools in just a few simple steps. Combined with a complete code execution framework, Hiplot allows all users to share their results.
The tools that you can share on Hiplot’s website are mainly divided into two types:
Cloud Tools, which adopt a front-end UI for setting parameters and a back-end program for executing computation code (currently only supporting R language, with plans to expand in the future).
Shiny Apps, which are Shiny applications written in R language, presented in the form of standalone websites.
Regardless of the type of application you upload, you must first apply to become a developer. Afterwards, in the Personal Center - Developer Dashboard, you can complete the editing and uploading of your tools. The development and upload of Cloud Tools will be specifically introduced below. Prior to this, you can gain some preliminary understanding of Hiplot tool development through this video: https://www.bilibili.com/video/BV1iD4y1v78T/
2.2 Become a Developer
Before uploading any tool, you must first apply to become a developer. You can complete the application for developer privileges in the Developer Dashboard in your Personal Center. To apply, you must bind a mobile phone number and a WeChat ID, and fill in some related information, which is only used for withdrawal and money transfer purposes. You can also upload a PDF résumé (optional) to introduce your related work, which will aid us in reviewing your application and possible follow-up collaboration.
2.3 Introduction to Cloud Tools
Cloud Tools consist of a front-end interface and back-end computation code. During the tool execution process, users upload data files or load examples through the front-end interface and set execution parameters using inputs, drop-downs, and other controls. Upon submission, data and parameters are passed to the back-end in file and JSON format, invoking the Hiplot Tool Execution Framework, which parses various parameters and calls the computation code, also handling communication between the front-end and back-end. When the computation code execution is complete, the Execution Framework returns the output results and logs to the front-end for display or download. At this time, the R process does not end immediately. If users only modify parameters and not the input files, the computation code will be re-executed in the same R process to save time.
The front-end UI interface is automatically generated by the Hiplot website. Throughout the process, there is no need to write any code—just configure the parameters and use the What You See Is What You Get UI drag-and-drop components to design the tool interface you envision. The back-end code consists of the Execution Framework and computation code, with the Execution Framework provided by Hiplot. You can easily access input files and parameters in your computation code and provide output files to the front-end, allowing you to focus on developing the computation code and save effort.
Next, we will introduce the methods for designing the front-end interface and the standards for back-end code, provide tool templates, and local debugging methods. You can first download and try out the template tools, and then read this document for details.
2.4 Front-End Interface Design
The main components of the Cloud Tool front-end interface are as shown below.
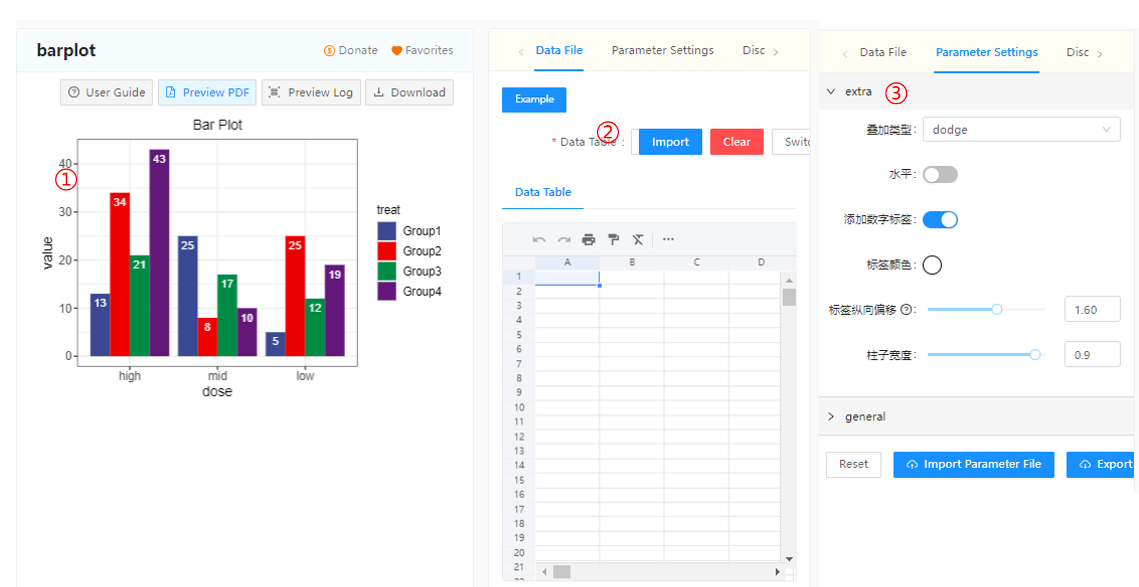
Figure2.1: Cloud Tool Details Page
The first part includes the tool name, usage guide, result display, etc. The second part pertains to data input, including samples, data upload, and data preview. The third part involves parameter settings, which include 1 to 3 collapsible parameter menus, each containing several controls responsible for setting parameters. All of the above contents are designed on the Developer Dashboard page without the need for coding.
Go to the Personal Center - Developer Dashboard and click on New Tool - Submit Source Code to enter the front-end interface design page. During this process, you will need to enter basic information about the tool and design the user interface contained in ② and ③. The entire process includes two steps: 1. Information Entry; 2. Custom Parameters. You can click the Temporary Save button below after completing each step to save progress. Detailed instructions are as follows.
2.4.1 Information Entry
In the first step of information entry, the following content should be completed:
Tool Name: Please enter the tool’s name in both Chinese and English, where the English name can only include letters, numbers, and underscores. Separate multiple words with underscores. Both Chinese and English tool names must be unique. You can avoid duplication with other tools by adding underscores and suffixes.
One-Sentence Introduction:Please enter a brief introduction in both Chinese and English (English is not mandatory; if not provided, the Chinese introduction will be displayed in English mode). This will be displayed on the tool list page and can be indexed by the search tool.
Upload Cover:Please upload a cover image, with a recommended resolution of 110*140 and a file size under 100kb.
Category Settings:Select the primary category for the tool, which appears in the left menu bar.
Subcategory Settings:Select the secondary category for the tool, which appears at the top of the list page. If the necessary category is not included, you may provide feedback on the right side of the page.
Tag Selection:Add tags to the tool, supporting up to three tags, which users can use to filter tools. If the desired tags are not available, you may provide feedback on the right side of the page.
Programming Language:Please select the programming language used by your tool. Currently, only R language is supported.
Output Result Type:Select the type of computation results you want to display on the tool details page. Currently, images (jpg, jpeg, gif, and png), tables (xlsx, xls, and csv), HTML files, and PDF files are supported for display. You can also choose not to display output results. For results files of other types, they can only be offered for download.
Whether to Charge:Indicate whether the tool is free or not. If charging a fee, you can define the number of free trials and the Hi-coin deduction ratio (part of the tool’s fee can be withdrawn in the Developer Dashboard, while the acquired Hi-coins can improve the developer’s level).
Usage Guide:Write usage guides in both Chinese and English (English is not mandatory; if not provided, the Chinese guide will be displayed in English mode). This information can be viewed on the tool details page. It is not recommended to use a large number of high-volume images. If you want to upload a video, it is recommended to first upload it to another platform and embed it into the guide. The image below uses bilibili as an example. Click Share - Embed Code, copy the embedded code, click on the video in the guide editor - insert video, paste the code you just copied and insert it.
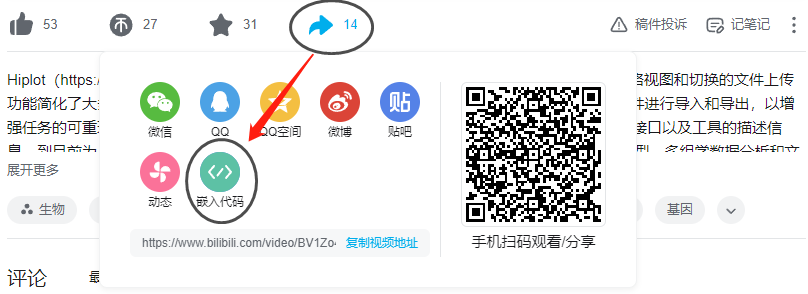
Figure2.2: Share Third-Party Video
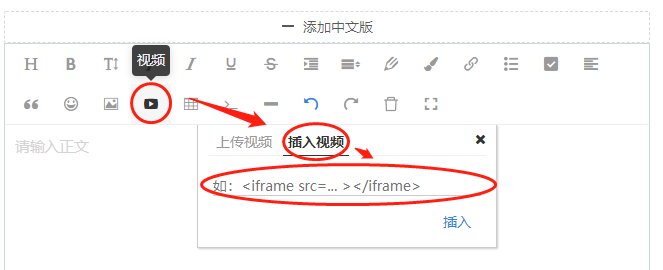
Figure2.3: Insert Third-Party Video
Whether to Delegate Deployment:If you find UI design and coding standards daunting, you can purchase our deployment service in the Cloud Market - Service Mall. If you choose this option, you only need to upload your computation code, and the Hiplot team will complete the tool deployment based on the information you provide. After deployment, you can modify the basic information at any time. As long as the computation code is not modified, deployment fees will not be charged repeatedly. If you need deployment, please provide a detailed introduction to the usage of your code in the tool package information, including the data input format, output results format, and needed parameters, to facilitate our deployment.
Tool Package Information:Please briefly introduce the function of the tool you are submitting, software version, and important dependency package versions, etc.
2.4.2 Custom Parameters
In the second step of custom parameters, you need to create all content on the right side of the tool details page, including data input and parameter settings.
Data File and Sample Upload:This section defines the input data file of the tool. Hiplot supports 0 to 3 input data files (added/deleted through the recycle bin icon on the top right corner or the add data button at the bottom), and the system will pass the path of each user-uploaded data file to your computation code (sample files are handled the same way as regular data files). Each data file needs to set the following content:
Data Field: The variable name used when passing the data file path, which will be used in the computation code
Chinese Name: The Chinese label of the data displayed on the tool details page is for display purposes only
English Name: The English label of the data displayed on the tool details page is for display purposes only
File Type: Please select the supported file extension for upload (if the desired file extension is not included, you may provide feedback on the right side of the page), which is only used to filter the file extensions of user-uploaded files
Upload Sample: Please upload a sample file in the supported format for tool demonstration, preferably with a smaller size for user convenience. This sample file will load when the user clicks the “Sample” button, with its path passed like that of regular data.
Note: The number of uses of a tool is calculated based on input files. Without changing the input files, no matter how the parameters are modified, it is treated as a single use and will not incur additional charges. Also, using the sample does not result in charges.
Custom Parameters:This section defines the computational parameter settings and UI of the tool. To keep the interface clean and aesthetically pleasing, Hiplot classifies parameters according to their functions, with each set of parameters displayed in a collapsible menu. Hiplot supports 1 to 3 collapsible parameter menus (added/deleted through the recycle bin icon at the top right corner or the add data button at the bottom), and the system will pass all parameters to your computation code. Each parameter set contains the following parts:
Chinese Tag: The Chinese label of the collapsible menu displayed on the tool details page is for display purposes only
English Tag: The English label of the collapsible menu displayed on the tool details page is for display purposes only
Field Name: The variable name used when passing the parameter set, which will be used in the computation code
Edit: Use the visual UI interface design tool to edit the parameter input page. Detailed instructions are provided in the next section.
2.4.3 UI Design Tool
In the custom parameters interface, each parameter set features an edit button, which displays the UI design tool after clicking. This allows you to design the UI for each parameter set independently, as shown in the figure below.
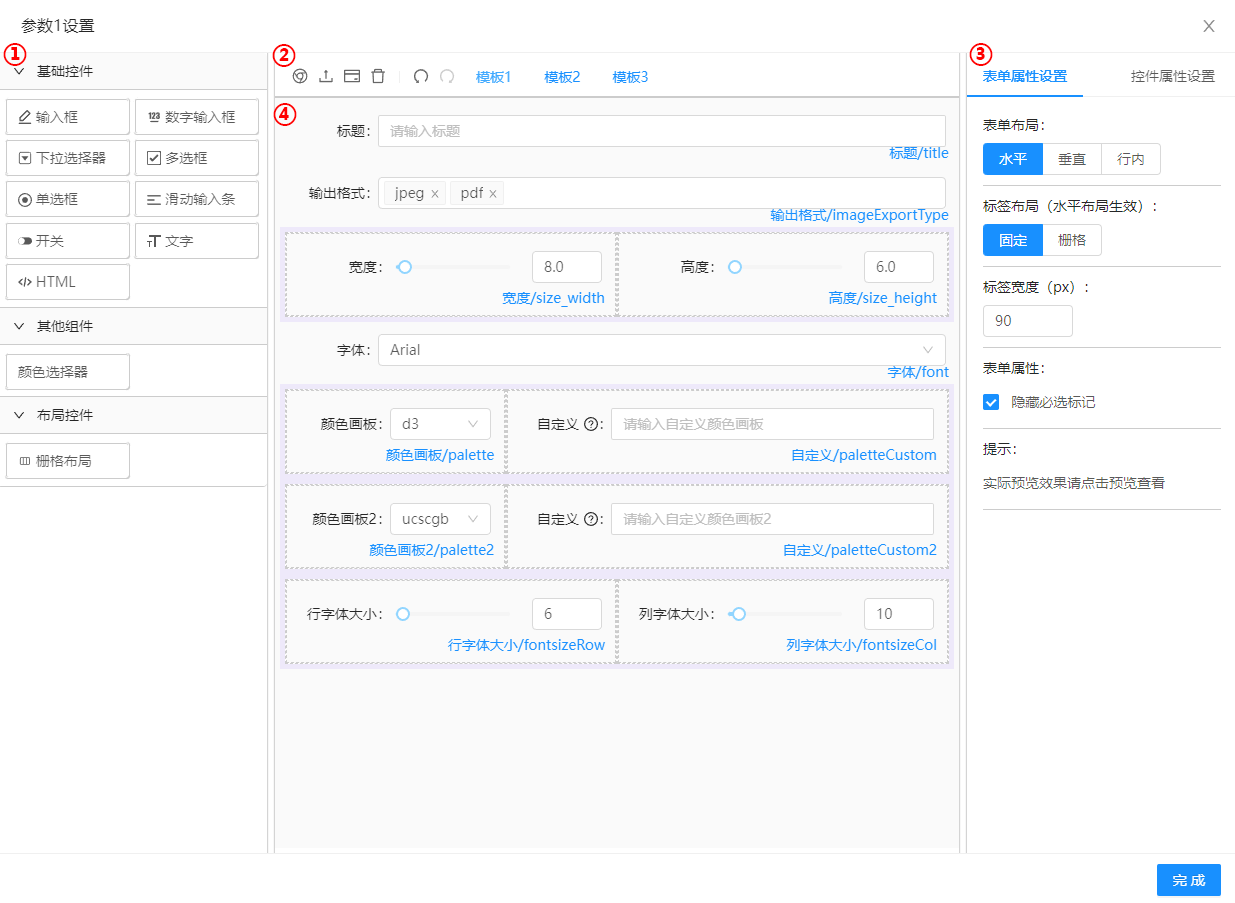
Figure2.4: UI Design Tool Introduction
This page includes four main parts, where ① is the control selection area; ② is the functional button area; ③ is the detailed settings area; ④ is the control operation area. During use, first select the desired controls from ①, preview and adjust their positions in ④, set control properties in ③, and use a variety of functions provided in ②. Detailed instructions for these four parts will be provided next.
First is the control selection area, which includes basic controls, other components, and layout controls. Below are the parameter types corresponding to each control: input box, drop-down selector, radio button correspond to strings; number input box, sliding input bar correspond to numbers; check box corresponds to an array of strings; switch corresponds to a boolean variable (true or false); color selector corresponds to a six-digit string starting with #; text, HTML, and layout controls do not correspond to parameters but are used to beautify the interface and provide additional features. You can freely select these controls based on your required parameters and interaction types.
Next is the functional button area, which from left to right includes: Preview, which previews the UI effect at the actual interface width and allows you to modify content and obtain the modified parameter JSON file; Import, which generates an interface based on the imported UI JSON file and can be used in conjunction with the Generate JSON button below; Generate JSON, which produces a UI JSON file based on the current UI settings, which can be manually modified or used for import; Clear, which clears the page content; Undo and Redo. There are also three UI templates available for reference.
Then is the detailed settings area, which contains the form attribute settings and control attribute settings. Form attribute settings allow you to set entire form properties, such as layout, label width, etc. Control attribute settings vary by control and can be experimented with independently. Common content includes Label (text displayed on the interface), Data Field (the variable name used when passing the parameter, to be used in code writing), Default Value, Help Information, etc. Each control must set Label, Data Field, and Default Value.
Finally is the control operation area, where you can perform drag-and-drop and other operations on the controls, designing the UI layout in a visual, WYSIWYG manner. Controls can be copied and deleted, and by pairing with grid layout controls, you can design a clean and easy-to-use UI interface.
After the above design is completed, the front-end interface design is officially finished. You can proceed to modify the back-end code. In addition, there are some optional features available during the front-end interface design process, which will be introduced below.
2.4.4 Additional Features
For charged tools with trial uses set, if you only wish to provide partial features rather than full functionality to trial users, you can design a special parameter UI file for trial users. When conditions are met, a trial version parameter file upload option will appear at the bottom of the custom parameters. The use method is as follows:
First, design the data file and custom parameters as usual. After the design is completed, click the Next Step button. The dialog box shown in the figure below will pop up.
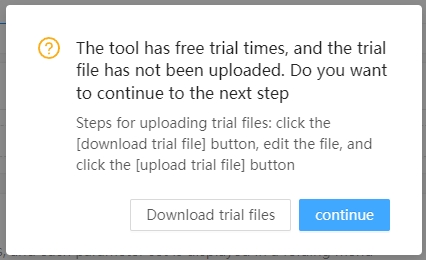
Figure2.5: Design the Trial Interface
If this feature is not required, you can simply click Continue. If you wish to design a trial UI, first download the trial file, which downloads a JSON file identical to the formal UI file. You can modify this file and rename it to ui_trial.json, then upload it in the Upload Trial File option. Below we will introduce the structure of this JSON file and recommended modification methods.
{
"data": {
"data1": {
"type": "hiplot-textarea",
"label": {
"US": "test",
"CN": "测试"
},
"required": true,
"fileType": [
"txt",
"csv"
]
}
},
"param": {
"var": {
"label": {
"US": "test",
"CN": "测试"
},
"ui": {
"list": [
{
"type": "number",
"label": "数字输入框",
"options": {
"width": "100%",
"defaultValue": 50,
"min": null,
"max": null,
"precision": null,
"step": 1,
"hidden": false,
"disabled": false,
"placeholder": "请输入"
},
"model": "number",
"key": "number_1652841157303",
"help": "",
"rules": [
{
"required": false,
"message": "必填项"
}
]
}
],
"config": {
"layout": "horizontal",
"labelCol": {
"xs": 4,
"sm": 4,
"md": 4,
"lg": 4,
"xl": 4,
"xxl": 4
},
"labelWidth": 100,
"labelLayout": "flex",
"wrapperCol": {
"xs": 18,
"sm": 18,
"md": 18,
"lg": 18,
"xl": 18,
"xxl": 18
},
"hideRequiredMark": false,
"customStyle": ""
}
}
}
}
}The UI json file contains two parts: data and param. The data section may include 0 to 3 data inputs, whose field names are set by the user. The content’s label is a bilingual tag set by the user, and fileType is a file extension setting also set by the user; other content does not need to be modified. The param section contains 1 to 3 sets of parameters, whose field names are set by the user. The content’s label is a bilingual tag set by the user, and ui is the json file output from the UI editor, which can be directly replaced by the exported json file from the UI editor. The following details the json format for a single UI interface.
The json exported from the UI editor mainly consists of two parts, list and config. The list is an array, with each widget corresponding to an element within it. Within the list, type corresponds to widget type, model corresponds to data field, label corresponds to the tag, and the remaining content corresponds to the settings in the widget properties. A special case is the key, which is built into the editor and does not need to be modified as it does not affect usage.
Recommended modification method:If you wish to design special parameters for trial users, Hiplot recommends that you do not add or delete widget types to avoid problems with tool operations. Instead, set key parameters to a disabled state and set default values that are applicable for all scenarios. In this case, trial users will not be able to modify the content of specific widgets and can only use the default parameters. The method of modification is as follows: in the options of the widget that you want to disable within the list array, set disable to true, as shown below.
{
"list": [
{
"type": "number",
"label": "数字输入框",
"options": {
"width": "100%",
"defaultValue": 50,
"min": null,
"max": null,
"precision": null,
"step": 1,
"hidden": false,
"disabled": true,
"placeholder": "请输入"
},
"model": "number",
"key": "number_1652841157303",
"help": "",
"rules": [
{
"required": false,
"message": "必填项"
}
]
}
],
"config": {
…
}
}2.5 Backend Code Standards
In the final step of creating a new tool - uploading the code package, you need to package your computational code in zip format and upload it. Before completing the final step of submitting for review, you must modify your code to comply with Hiplot’s specifications. Don’t worry, Hiplot also provides a local testing environment for you to test, and the method of use will be introduced at the end of this section.
Hiplot’s coding execution framework implements most of the parameter parsing, communication, and control functions, allowing developers to focus as much as possible on data computation and analysis. However, to adapt to the Hiplot framework, you still need to make minimal modifications and adhere to standards with your computation code. The following will introduce methods for backend code modifications, and at the end, a template for reference and debugging is provided.
2.5.1 Minimum Implementation Method
Hiplot’s code execution framework offers a plethora of functionalities, but if you want to quickly launch your tool and become familiar with the system, you can refer to this section on the minimum implementation method, which only provides the minimum modifications needed to make the tool function correctly.
1、The data files defined in the custom parameters section will be uploaded as regular files, and you can obtain their path in the tool code. Please use conf\(data\)[your defined data file field name] to get the path of the file, as shown in the figure below, where the data file can be obtained through conf\(data\)ExpMatrix.

Figure2.6: Data Setting Interface
Subsequently, you can use any function to read the file, like
read.table(file = conf$data$ExpMatrix)
2、2、For the input parameters defined in the custom parameters section, please use conf\(param\)[your defined parameter dropdown menu field name]\([control field name defined in the UI editing interface] to get them. As shown in the next figure, the parameters can be obtaine through conf\)param\(genera\)ltitle, where you will get the string entered by the user in that control.

Figure2.7: Dropdown Menu Setting Interface
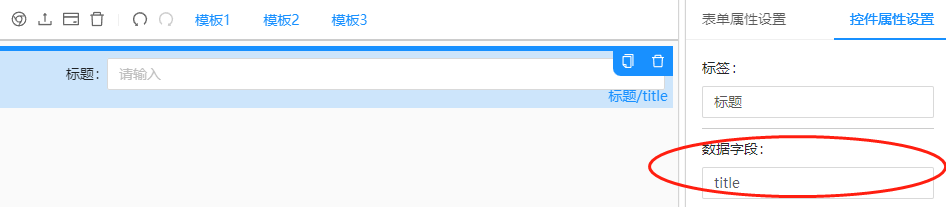
Figure2.8: Parameter Setting Interface
3、Any output file you want to display or provide for users to download must use the get_file_path(filename) function to obtain the output file path for two purposes: 1. To standardize the output directory, 2. To provide all output files to the frontend. The filename is a file name string, which can be arbitrarily specified, and the function returns an output path (including the file name) string. You can output the file in any way, such as
save(list = c("data"), file = get_file_path("test.Rdata"))
save_plot(p, filename = get_file_path("nonsense.pdf"))
file_path <- get_file_path("data.txt")
write.table(data, file = file_path, sep = "\t")Please note that after using the get_file_path function, you must output the corresponding file when the run is finished; otherwise, the tool will report an error. If there are intermediate process files that are not important, you can deal with them at your discretion, and no deletion operation is needed.
4、You only need to upload your computational code and other dependent files (compressed together in zip format), and your code entry must be named plot.R. If you need to refer to other files, compress them with plot.R when uploading, and add the content folder before the file name when referring to them, like
source("content/dependencies.R")2.5.2 Optional Advanced Features
Please make sure you have read the minimum implementation method before moving on to this section. In the minimum implementation, you are already able to build an executable tool, but this section will introduce all the features provided by Hiplot’s code execution framework, allowing you to fully optimize your tool, enhance the user experience, and unlock the full potential of Hiplot.
Speed up the calculation process
After the tool has executed, Hiplot does not end the R process for a period of time. As long as the user does not change the input files but only modifies parameters, the tool will continuously execute in the same R process, which enables us to optimize the execution speed of the tool from two aspects.
1、 Improve initialization speed
The initialization steps of the tool include loading R packages, reading data, and preprocessing, etc. Since the input data will not be modified during a single calculation, these steps can be executed only once. Hiplot provides the conf$taskType field to determine whether the tool is running for the first time. When running for the first time, the value of this field is ‘origin’, and by judging this value, you can selectively skip the steps of reading data, preprocessing, and initialization. Note: If you want to use this feature, you must not modify the original data read in during the analysis and plotting process; if you need to modify, it is recommended to create a copy and modify it on the copy.
2、 Avoid repeated calculations
Many times a tool includes both data analysis and plotting output steps. In cases where only the plotting output parameters have been modified, it is possible to avoid repeating the data analysis steps and thus improve the running speed. To achieve this, you can set the analysis parameters and plotting parameters in different parameter collections, and then skip some time-consuming analysis steps by judging whether one or more of the collections have changed. Example code is as follows:
if (!(exists("conf_param_pre") && all(conf_param_pre == unlist(c(conf$param$dataArg, conf$param$extra))))) {
conf_param_pre <- unlist(c(conf$param$dataArg, conf$param$extra))
# 您需要跳过的分析步骤
}Real-time status feedback and logs
Currently, in R language, the status_report function can be used to provide real-time updates of the tool’s status to the website. Currently, there are four selectable statuses:
status_report("reading", socket)
status_report("analysing", socket)
status_report("plotting", socket)
status_report("outputting", socket)Under these four statuses, the front end will automatically display corresponding bilingual labels. If you want to customize the content displayed on the front end, such as displaying a percentage of calculation progress, please use the following function to send a json string:
writeLines('{"msg_type":"status_report","status":"initializing","US":"initializing","CN":"正在初始化"}',socket)You need to modify the json string in the content of the status, US, and CN sections, where ‘status’ must be anything other than ‘initializing’, ‘idle’, and the four statuses mentioned above, and CN and US are the text content to be displayed in Chinese and English status, respectively.
Note: Custom display may not work properly in local testing, so please delete this part during local testing. The four preset statuses of the status_report function can be used during local testing.
In addition, you can freely add content to the logs, which will be displayed to users at the end of the run. You can use functions like print that directly output content to the console, and the output content will be saved in the logs.
Special output files
In general scenarios, you only need to get the output file path with get_file_path and register the output file. However, in some cases, this may not be particularly practical, such as when the R package you are using outputs files with fixed names and paths. In these situations, you can process these output files yourself, mainly involving the following two steps:
1、Place the output file in the [current working directory/output/] folder.
2、Register the output file, you need to append the file name to the outputFileList variable, excluding the output folder, only the file name is needed, and please note that you should use <<- for the assignment. An example is shown below:
outputFileList <<- append(outputFileList, "output.pdf")Batch output of multiple output files
In some cases, output files for display are generated quickly, but some outputs for download only (e.g., a plotting tool generates PDF plotting results for display on the interface but also generates HTML and DOCX format reports for user download) take longer to produce. In these instances, the batch output feature can be applied. You only need to execute the following R statement after the results file for display (e.g., the PDF file in the example) is completed:
check_results(outputFileList, "first")This will enable the functionality. The website’s front end will directly display your results, but the download button will be temporarily disabled until all calculations are completed, and then all results will be offered for user download.
2.5.3 Testing Environment and Template Usage Methods
Hiplot provides you with a local testing simulation environment and tool templates for reference. You can download the local testing environment on the developer dashboard - create a new tool - upload tool package page at the bottom of the download test environment button.
To test your own tool, you need to prepare the following:
1、Download the JSON file by clicking the download configuration file button at the bottom of the Create Tool - Upload Tool Package page, download the testing environment, and unzip it.
2、Place the tool package (containing the plot.R file) in the content folder of the test environment.
3、Rename the downloaded configuration file to config.json, put it in the content folder, and check that the data file names and parameters in it are correct.
4、Place the sample data corresponding to the file names in config.json in the data folder.
5、Use the command line to run Rscript .\run.R in the outermost directory for testing, or set the working directory to the test environment directory in Rstudio and run run.R for testing.
6、The logs and output files can be seen in the output, and the log should have a list of output files at the end, indicating a successful run.
7、At this point, you can package all the contents inside the content folder into a zip file and upload it.
2.5.4 Reserved Variable and Function Names
In code writing, you should avoid using the following names as variables or functions, including:
socket
opt
taskID
outputDir
outputFileDir
inputFileList
outputFileList
conf
publicConf
taskStartTime
outputByStep
init_hiplot
init_hiplot_standalone
init_hiplot_connected
hiplot_command_handler
run_hiplot
eval_parse_codes
check_results
get_file_path
get_filename
status_report
get_suffix2.6 Shiny Tool Submission
The submission of Shiny tools is relatively much simpler due to their encapsulation nature, and it only requires completing information entry. It is worth noting that if you have completed the development of a Shiny tool but do not have a server, you can opt for Hiplot’s deployment service to complete the deployment. For detailed information, please refer to the introduction and help info on the corresponding page.
2.7 Developer Experience Points
About the Experience Points Level System
To reflect the activity level, popularity, and professionalism of resident developers, the Hiplot platform implements an experience points accumulation and level growth system for all developers. The developer level is determined based on the experience points obtained by the developers, and now the rules for obtaining experience points and the level growth system are limited and made public. Developers can inquire about their developer levels in the “Developer Dashboard”. Experience points are not currently displayed, but future version updates will show developer experience points and upgrade progress.
Earning Experience Points
Developers can earn experience points through the following four methods, including Hi coins and the usage of developed tools. For rules regarding the acquisition of Hi coins, please see the Hiplot platform’s rules for acquiring Hi coins.

Figure2.9: Experience Acquisition Rules
Experience points will not be deducted for tools that have been taken down by the developer or deleted due to violation of platform management regulations after the tool has passed the online review process. If a tool fails to run during use, experience points will not be deducted.
Developer Level Corresponding to Experience Points
The developer level is determined by the accumulation of experience points. As experience points accumulate, the developer level increases. The correspondence between developer level and experience points is shown in the following table:

Figure2.10: Developer Level
Disclaimer
Hiplot is not liable for any legal responsibility in the following situations:
1.Loss incurred by a user due to the sharing of their password with others;
2.Losses caused to a user by their own intentional or gross negligence, or by third parties not within the scope of this agreement;
3.Various circumstances and disputes caused by force majeure and unforeseen situations, which include but are not limited to: hacker attacks, government control, virus infections.
2.8 Python Tool Development
Python Code Modification Guide
Hiplot’s built-in programming framework has completed tasks like parameter parsing and communication, so you only need to focus on writing your computational code. Before uploading tool code, you may need to pay attention to and modify the following points:
1、For the path to data files, please use conf.data.[your defined data file field name] to obtain it, such as conf.data.ExpMatrix. You can use any function to read this file.
2、For user-entered parameters, please use conf.param.[your defined parameter dropdown menu field name].[control field name defined in the editing interface] to obtain them, such as conf.param.general.title. The parameters you get will be consistent with what you see in the UI editing and preview interface.
3、Any output files that you want to display or provide to users for download must be accessed using the get_file_path(filename) function, where “filename” is a string for the file name that you can specify freely. This function returns a string with an output path (including the filename), and you can use any method to output the file. Please note that if you use the get_file_path function, you must produce the corresponding file after running. For unimportant intermediate files, you can handle them at your discretion without needing to delete them.
4、You only need to upload your computational code and any other dependent files (compressed in ZIP format). Your computational code must be named plot.py.
5、If you need to reference other files, please compress them with plot.py and upload them, and use them by referring to the relative directory “./content/[your file]””“, such as”./content/dependencies.py””“.
6、Please be sure to fill in the necessary dependencies or runtime environment information to ensure the successful deployment of the tool.
Additional Optional Features:
Following the five points above will ensure that your tool runs successfully; moreover, to enhance user experience, Hiplot offers the following optional features:
1、The conf.taskType field is provided to determine if the tool is running for the first time. If it is the first run, the value of this field is ‘origin.’ By checking this value, you can opt to skip steps like data reading and initialization; furthermore, you can set calculation parameters in a separate set and determine whether to skip certain time-consuming computational steps by comparing changes in parameters.
2、Use the status_report function to report the tool’s running status to the website. Currently, there are four types of status:
status_report(“reading”, conn) status_report(“analysing”, conn) status_report(“plotting”, conn) status_report(“outputting”, conn)
3、If you need to output content in the log, you can use the logging.info function.
4、Refer to the guide for the R language section for other matters.
Debugging Methods:
Hiplot provides a simulation running environment for debugging your computational code. First, download the configuration file and testing environment and unzip them. Then, follow the steps below for local testing. Only after everything is working normally should you upload the code.
1、Place the tool package in the content folder of the testing environment.
2、Rename the downloaded configuration file to config.json, place it in the ‘content’ folder, and check if the data file names and parameters are correct.
3、Place the sample data corresponding to the file names in the ‘config.json’ into the ‘data’ folder.
4、Run the command python ..py from the top-level directory for testing, or use other software for testing.
5、You should see the logs and output files in the ‘output’ folder. The end of the log should have a list of output files.